[Modern Data Warehouse] Serverless databases – what are they and when should you use them?
21 October 2021
Key points:
- Provisioned capacity for PaaS database – does it always meet current trends in programming?
- What is a serverless database and how does it differ from the database with provisioned capacity?
- What are the pros and cons of serverless databases?
- Scenarios for using serverless databases
Cloud databases have been available in the market already for some time and it seems like they are here to stay. Setting databases as Platform as a Service (PaaS) seems an attractive alternative to on-premises solutions for more and more companies.
Most commonly, the first step in creating a database in the PaaS model means choosing specific database parameters like CPU or database size so that you pay for the resources that you specify. That seems like a pretty transparent model of paying as you know precisely for what capacity you’re charged. If requirements and database usage patterns change, you can up-scale or down-scale it on demand.
However, this approach may not always be the most optimal one. Its weakness can be visible for example if we think about another trend provided in cloud solutions – serverless programming. Moving development into the cloud allows developers to develop applications without the overhead of managing infrastructure. Thanks to that you can be charged only in case of actual app execution and you pay only for the time your code is executed. Datadog’s 2021 The State of Serverless report shows growing interest in serverless computing among companies – AWS Lambda functions are invoked 3.5 times more often than two years ago, whereas the percent of Azure organizations using Azure Functions increased from 20 to 36 in the past year. 1
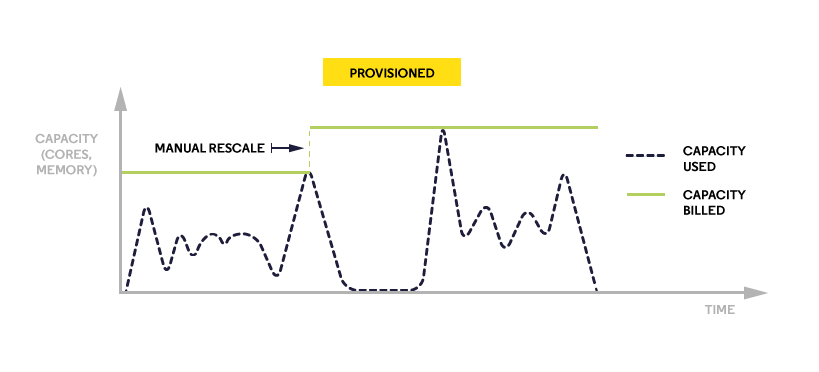
That can simplify the process of app development and give the possibility of cost optimization. However, if the application connects to a cloud database with fixed resources, it reduces the profits of serverless computing – even if the application is generating costs only when being used, costs of the PaaS database are fixed and scaling must be done manually.
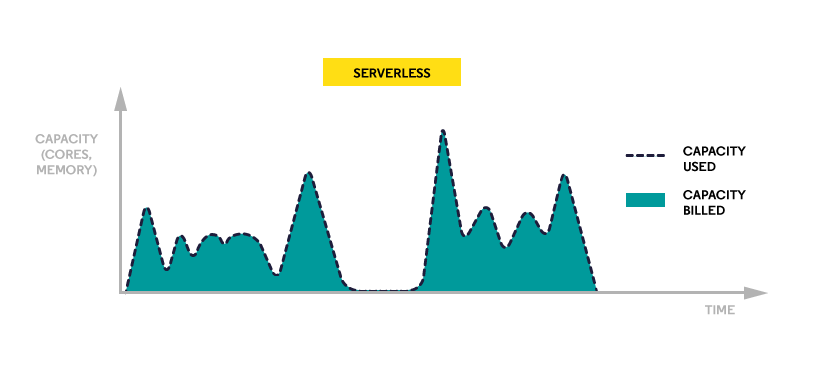
That’s where serverless databases may become useful. The word ‘serverless’ may seem a little confusing in this context as after all cloud databases seem to be ‘serverless’ to customers – you don’t handle physical infrastructure, although in reality there is always some server behind. However, here we refer to the word ‘serverless’ in the meaning of a solution that uses dynamic auto-scaling. The layer of having a server is thus even vaguer as you aren’t tied with provisioned capacity. You don’t have to plan resources for your database as everything is managed by the provider dynamically. The range of computing capacity can be configured so that you can be sure that your costs don’t exist certain level.
The charts below show the simplified comparison of the two models and how billed capacity differs between them:
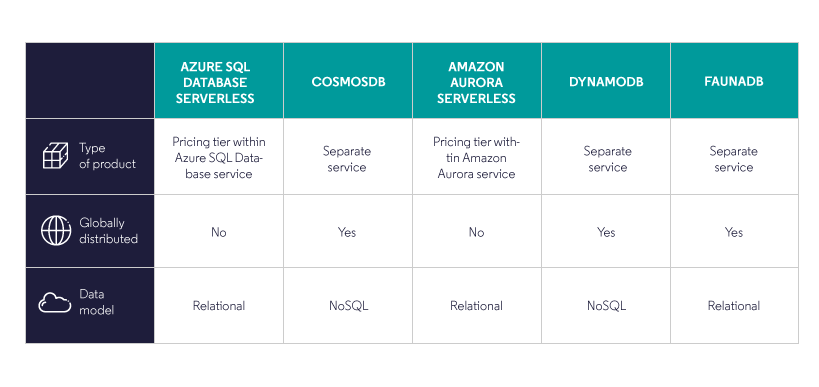
There are multiple options available on the market in terms of serverless databases. Depending on the vendor, they can be provided to you either as a separate service or as a special pricing tier within the existing one. Some of them are typical relational databases, whereas others are based on NoSQL models. To meet the demand for low latency applications, some of them are globally distributed.
So what are the advantages of serverless databases?
- Scalability and elasticity – continuous scalability as capacity is changed dynamically to meet the demand of workload
- Cost efficiency – when provisioning your database for a certain level of resources, you must pay a fixed amount unless you decide to rescale. It can lead to underutilization when you pay for resources that you don’t use
- Productivity – in addition to saving money, serverless databases can also save developers’ and administrators’ time. It’s the provider’s responsibility to scale the database dynamically less time is needed to plan scaling policy
It’s important though to remember that serverless databases can show sometimes slower latency in comparison with provisioned capacity. It may be associated with load balancing needed when upscaling resources needed to satisfy workload. Another example is the auto-pausing option, offered for example in the Azure Serverless pricing tier. A database can be auto-paused when it shows no sessions or CPU usage for a configured time period. It’s a good option to optimize costs when the database is not used, however, it can take a few minutes to auto-resume the database. In the case of applications with a predictable constant high workload where low latency is crucial, provisioned capacity can be the more suitable choice.
Considering the points above, there are a few scenarios where the serverless database can be a good choice:
- New applications and databases – when you don’t know exactly how load and pattern usage will look like and they are difficult to be estimated, the serverless database can give images of the situation without restricting resources
- Applications with irregular and infrequent usage – for applications that are used irregularly, serverless databases will keep costs low when the database is not in use
- Databases used for testing or development – often they aren’t used as regularly as production databases and thus can be good candidates for auto-scaling model