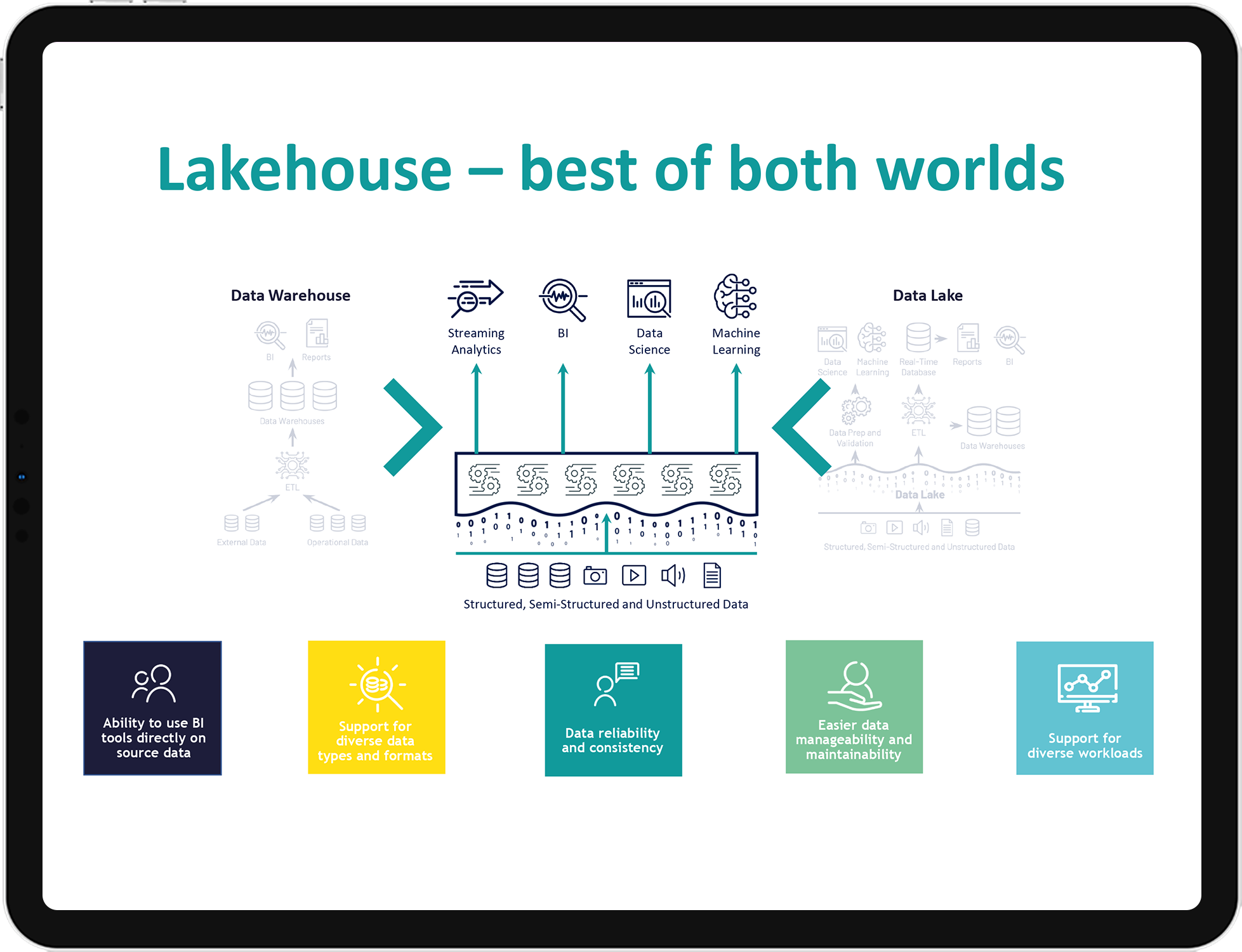
The Lakehouse Platform delivers data management and performance typically found in data warehouses with the low-cost, flexible object stores offered by data lakes.
This unified platform simplifies your data architecture by eliminating the data silos that traditionally separate analytics, data science, and machine learning. It’s built on open source and open standards to maximize flexibility. And, its native collaborative capabilities accelerate your ability to work across teams and innovate faster.
1. Dealing with shattered, fragmentized data all over the place?
Simplify your data architecture by unifying your data, analytics, and AI workloads on one common platform
2. Do you struggle with maximizing the potential of your data team?
Databricks Lakehouse Platform unifies data teams to collaborate across the entire data and AI workflow. All your data teams — from data engineers to analysts to data scientists — can now collaborate across all your workloads, accelerating your journey to become truly data-driven
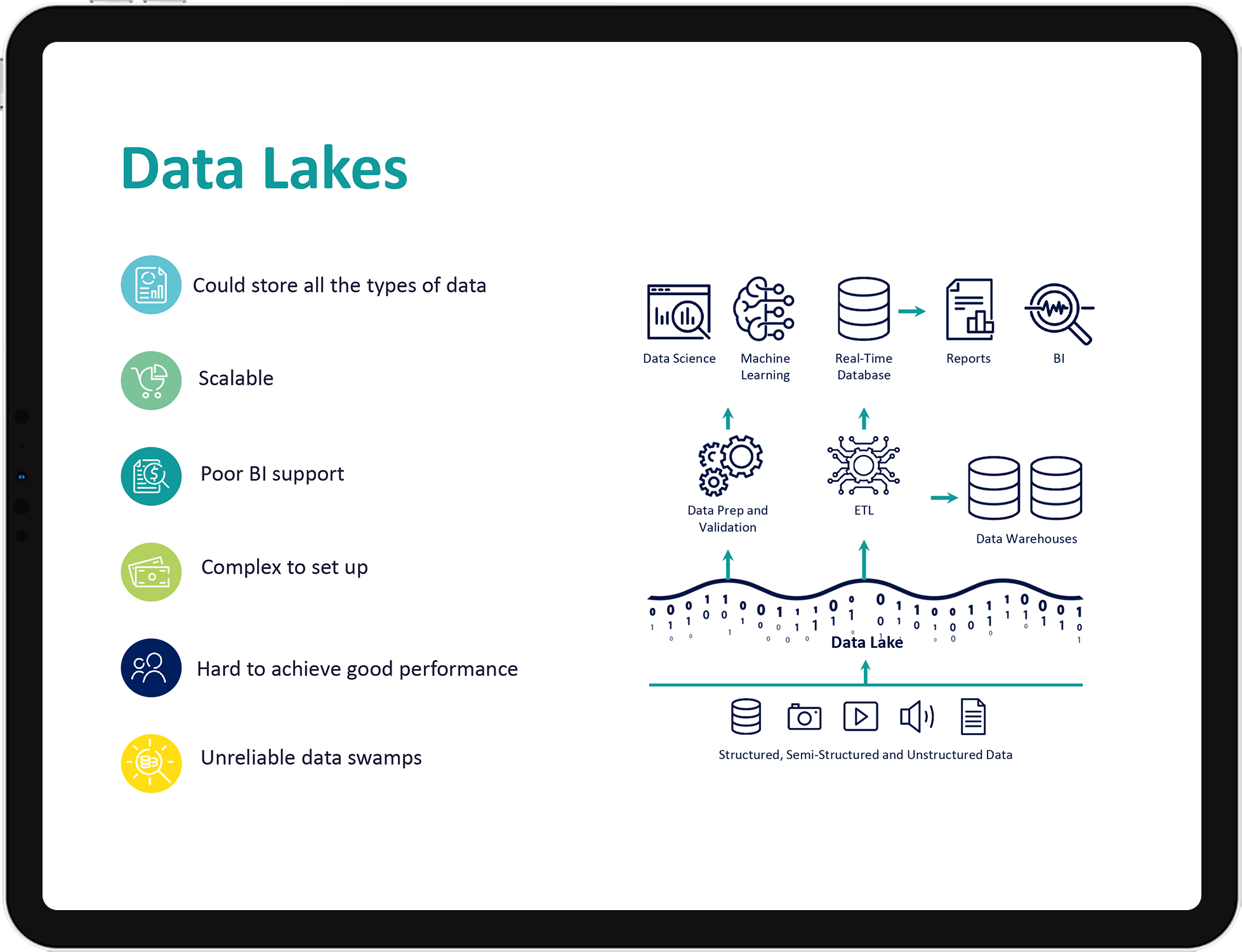
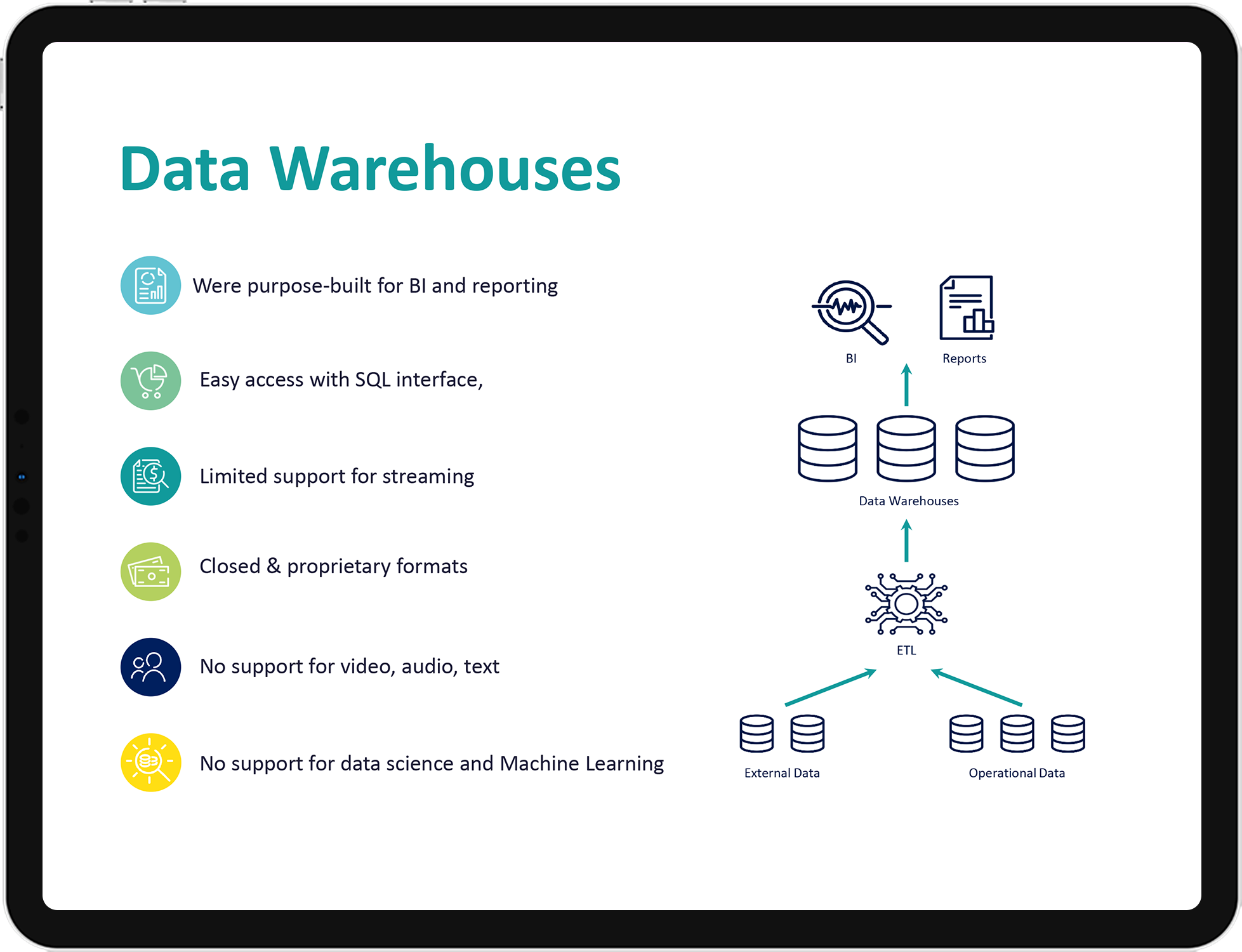
3. Do you have challenges with your Data Lake?
Lakehouses are enabled by a new system design: implementing similar data structures and data management features to those in a data warehouse directly on top of low-cost cloud storage in open formats.
They are what you would get if you had to redesign data warehouses in the modern world:
Don’t hesitate to schedule a meeting if you are interested in:
