Modern Data Science Toolbox – A Decade of Development
24 November 2021
Stairway to (Data Science) Heaven Series
Key Points:
- What was the last decade like in data analytics? What kind of progress has been made?
- What does Data Science bring to the business? What kind of companies can benefit from it?
- What does an example of a modern, cloud-based Data Science tool look like? What is in a Data Scientist’s Effective “Toolbox”?
The Golden Decade of Data Science
In recent years, Data Science has stormed the business world as a brilliant definition of statistical proficiency supported by the latest IT technologies. Although the concept itself is a very recent invention (in the present sense it is dated only in the early 2000s[1] ) – the area of effective use of data hidden under it has always been with us. Already ancient civilizations saw the remarkable benefits of using mathematics to solve current business problems (though I am sure it was called a bit different then!). It is enough to mention that the Rhind Papyrus[2] and Moscow Papyrus[3], well over three thousand years old, are in fact a collection of practical computational problems such as the division of food among workers or determining the angles of inclination of the elements of the building under construction. Ancient Date Scientists needed?
Holding on to more modern times, and more precisely in the early 2000s, a fairly common business scenario was the adoption of analytics using available office tools (such as Excel) or building data-science-like processes somewhere in the background, next to the main currents of data processing. The most popular solution was a pure database backbone (Oracle, Teradata) supported by an analytical layer (e.g., SAS, SPSS). People with a strong reporting base (including SQL) and certain skills in scripting languages, such as VBA or 4GL, were delegated to work on the data. The analyst of the time had to show the ingenuity of MacGyver to deliver business value through partially unrelated processes. They might not have a Swiss army knife and sticky tape in their arsenal, but a set of classic statistical methods instead: linear regression, Naïve Bayes, logistic regression, K-Means clustering, PCA, time-series methods like smoothing or ARIMA.
The situation began to change significantly with the emergence of the enormous possibilities offered by the open R and Python languages. The availability of ready-made libraries with algorithms, along with the systematic increase in knowledge of these languages in the industry (thanks to, among others, academic popularization) have shaken the position of the current leaders and set a new standard. The picture was completed with a kind of revolution in the approach to data processing – considering large volumes as an opportunity, not an obstacle. 2011 saw the release of the first “full” version of Apache Hadoop[4] 1.0.0, three years later Apache Spark[5] addressed many of its weaknesses. Along with these technological advances, the development of algorithms is taking place – the invention of new ones and a renaissance of the already slightly forgotten ones. Modern Data Scientist is more of a statistician than a report creator, and apart from data technologies, they know a wide range of algorithms, including XGBoost, Random Forests, Boltzmann Machines, genetic algorithms, various neural networks, and their extensions, e.g., generative adversarial network (GAN).
Thanks to the interest of technological giants, the last decade has been a kind of boom or even golden period of Data Science. It is true that humanity has not yet created artificial intelligence straight from science-fiction movies, but we have several equally important achievements to our credit. To mention a few of the most popular ones:
- In January and February 2011 IBM’s AI Watson[6] wins three sessions of Jeopardy! game show against living masters. The victory is guaranteed by several hundred methods of natural language analysis carried out simultaneously with advanced possibilities of searching for information on huge databases.
- In 2015, machine algorithms are doing better than humans in the annual ImageNet challenge[7] for the first time. It is the culmination of several years of improving image recognition algorithms.
- In March 2016, an AI called AlphaGo[8] by DeepMind won a GO game (long considered a too complicated thing for computers) against one of the best professional players, Lee Sedol, to repeat that result with other champions of the game in the following months. The strategy of maximizing the probability of winning implemented by AlphaGo turns out to be something new and difficult for people to interpret.
- In 2018, the first commercial autonomous car under the Waymo One[9] brand, equipped with a range of advanced sensors and cameras, is launched in Arizona. The four-stage analytical process goes from mapping the area to determining the safest route.
There is no doubt that we can expect more in the coming years!
Data Science in the service of modern business
The above cases certainly sound very spectacular, but the question naturally arises – are similar successes even within our reach? What kinds of industries can use Data Science to develop their business? I am in a hurry with the good news – every company can benefit from analytics! Thanks to the achievements of recent years, the so-called “entry threshold” for all interested in the benefits of data has dropped significantly, both in terms of the required skills and technological background. The only limitation – and an important requirement – is to have data on the problem we are interested in. But even in their absence, nothing prevents us from simply starting to collect them.
The profession of a barista at first glance is difficult to associate with the need for modern analytical methods. Meanwhile, the global success of the coffee giant Starbucks is largely based on data – classic ones, such as transactions, as well as completely new data from a mobile application, geospatial information, or machine sensor reading. Since the crisis in 2008, the company has been consistently investing in innovative technologies to build its technological advantage. Today, half of the transactions on the US market go through a loyalty program offering personalized promotions and recommendations, the company conducts constant data-driven research on new products, and dedicated AI optimizes the supply chain and property management[10]. Newer coffee machines, of course, report the need for repairs themselves… Apparently, it works[11]:
Data Science in a business context is not a strictly scientific activity, but still research – aimed at obtaining specific benefits. Most often it is the identification and implementation of new opportunities or cost optimization. This is best represented by four classic scenarios:
- Customer Segmentation – an answer to the need to handle the large variety of our customer portfolio. Data-driven segmentation is the process of dividing such a broad consumer group into sub-groups (known as segments) based on some type of shared (objective) characteristics. This allows for greater precision of actions, like building a more tailored offer or targeting x-sell.
- Classification and scoring (example: Fraud, the propensity to buy) – the art of assessing a transaction or a client in terms of two results: fraud/non-fraud, buy/non-buy, or whatever we are interested in.
- Churn Prediction – building the process of predicting and preventing customer churn. Varies by business profile – unsubscribing, lowering expenses, closing the product …
- Forecasting (example: Sales, Inventory) – the process of making predictions based on past and present data, including trend analysis and diverse types of external and internal factors. Building an answer to the question – what will a given quantity look like in the future? In recent times, a particularly popular field due to the turmoil caused by COVID-19.
Remember, however, that these are only canonical cases, and there can be many more applications of analytics. Even recognizing fish species[12].
From the point of view of benefits, a modern Data Scientist requires a specific set of tools to work effectively and carry out their mission of finding value in the organization. This toolbox should support the following core areas:
- Data extraction and storage
- Data transformation
- Modeling
- Visualization and storytelling
Single, dedicated tools in the classic form of utility software usually address only some of these points. Fortunately, the time of comprehensive solutions has finally come – thanks to the benefits of the cloud model.
Coming up with a Cloud
What exactly do cloud providers in the field of Data Science offer? First of all, a complete set of tools that allow you to build a fully-fledged, modern end-to-end scientific and business process. Thanks to the cloud model, both the necessary infrastructure and statistical tools are provided to us in a ready-to-use form. This is called the “ML as a service” model.
A quick look at the offer from Microsoft[13]:
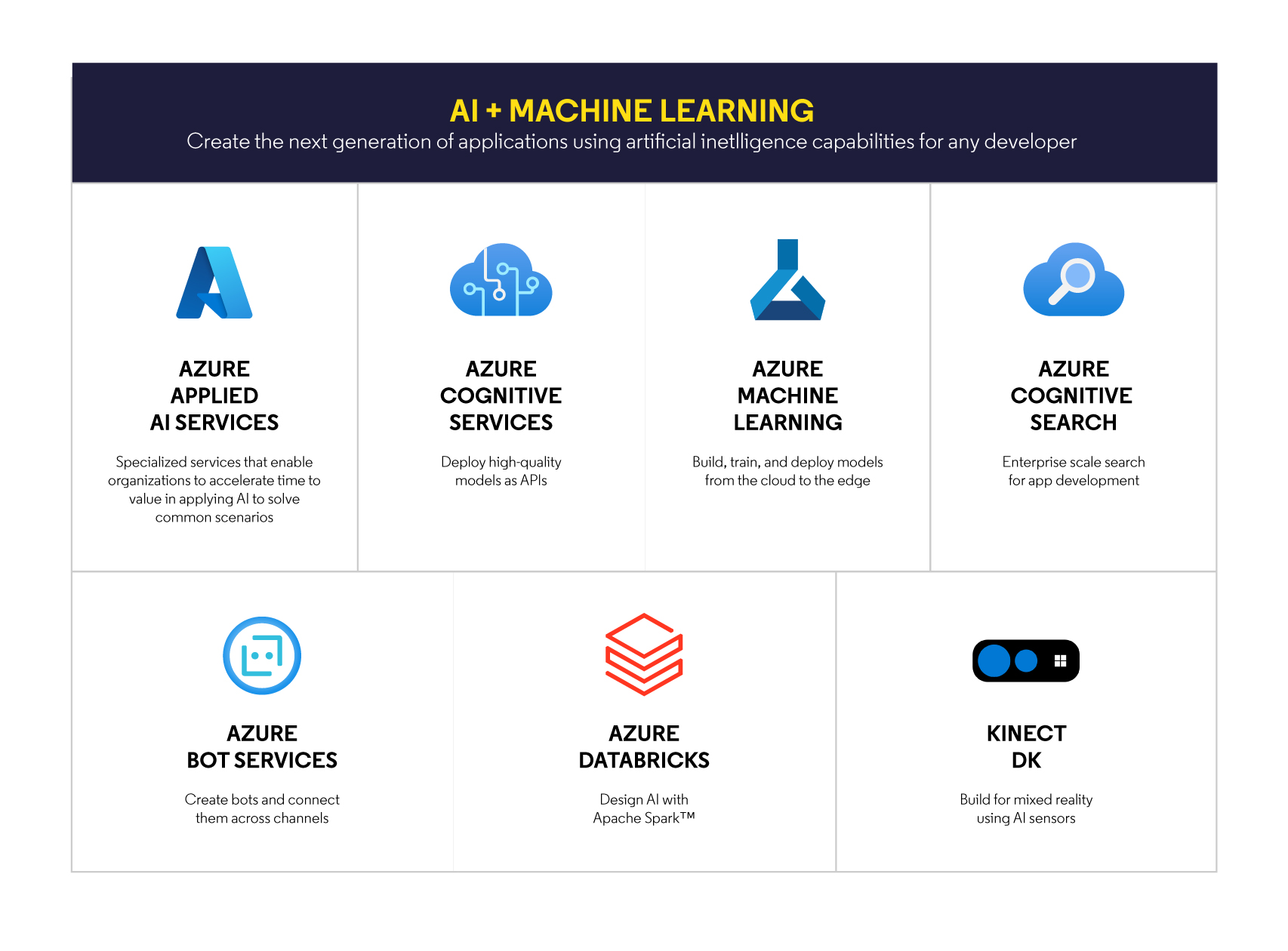
allows us to identify the main trends in contemporary analytical offers:
- Affordability – Delivering Machine Learning capabilities for all skill levels – from drag-and-drop creators to code writers.
- Comprehensiveness – providing support and tools for building processes from the beginning to the very end (meaning: from an experiment to production), without “dead zones” and understatements.
- Responsibility – building control over data, enabling understanding of models (including their strengths and weaknesses), and ensuring the security of the entire process.
- Flexibility – providing a wide range of options and services for various classes of problems (including support for various languages and frameworks: Python, R, Kubeflow, TensorFlow, ONNX …), scalability, and paying only for the resources actually used.
Note that these are exactly the challenges Data Scientists have faced in recent years. What is more, many problems that are already in some way standardized (classification of observations, recognition of text or objects in photos, translation, chatbots) have their own ready-made services, so one does not have to create them from scratch. ML as a service is designed to simplify our lives – in exactly the same way as other cloud solutions – today no one is surprised by the text editor available through the browser in the subscription service. The entire cloud ML design is to shorten the path to the business benefits.
Let us take a closer look at Azure Machine Learning, a kind of Data Science hub, which is the successor to ML Studio as the “command center” of our ML project[14]:

The panel on the left gives us access to several options that, until recently, required a number of different technologies. We have here in turn:
- Author section – enabling the creation and editing of Notebooks, a quick comparison of various machine learning techniques (along with various quality measures) on our data set and opening a graphic designer for modeling the ML workflow from the source to the model evaluation.
- Assets section – according to its name we can use it to manage all elements of our analytical work: data sets, models, parameters (experiments), and endpoints – i.e., access points from which we can connect to use the created ML solutions.
- Manage section – providing the necessary tools to manage computing power (single instances or entire clusters), storage of all objects (from data sets to models), or the integration of our ML processes with other services and systems.
All major supervised, unsupervised, and reinforcement learning algorithms are gathered as ready-to-use solutions. In other words, a modern toolbox is full of powerful options[15]:
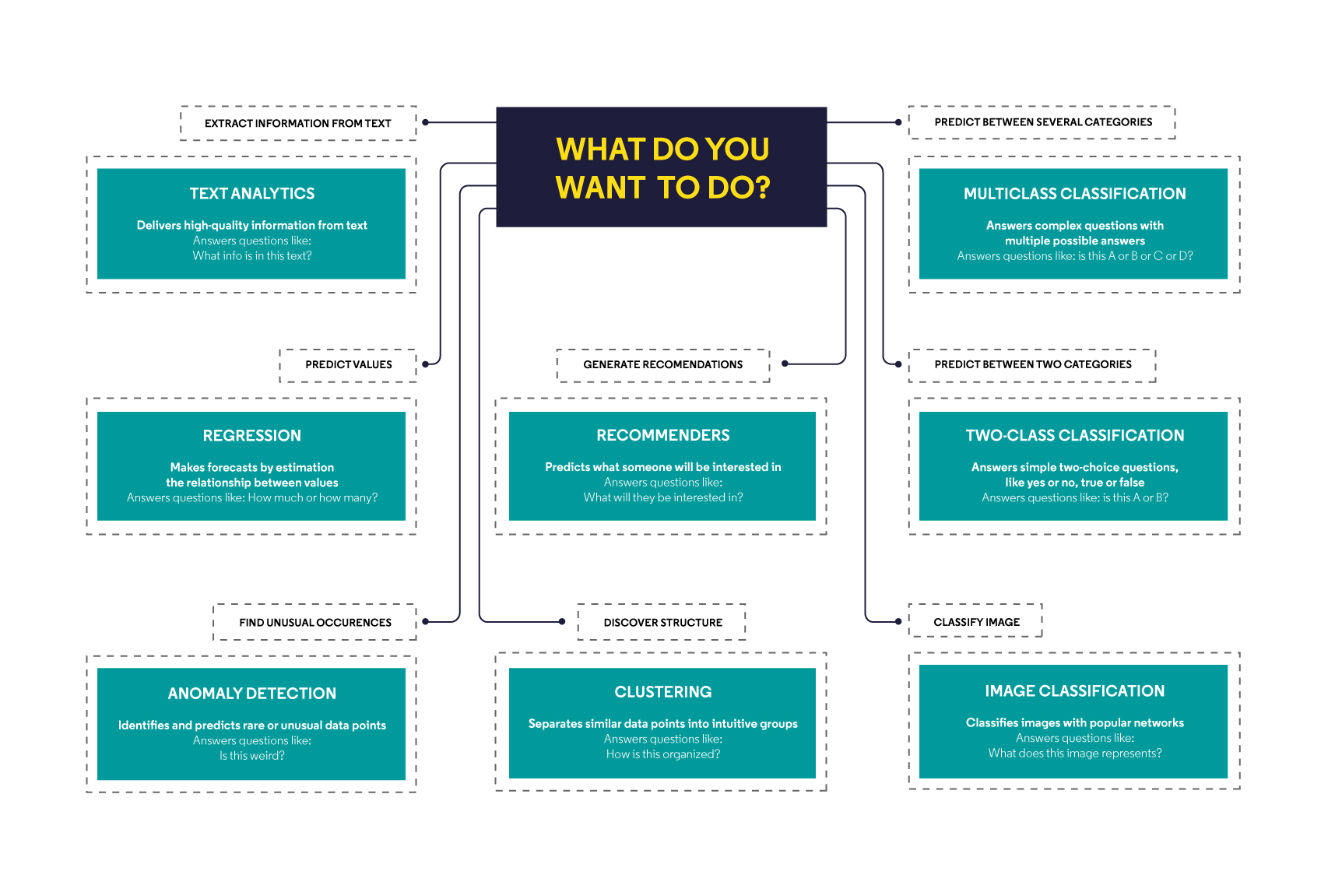
Both for people who remember the times of “translating” models into SQL, and for new Data Science adepts, this whole arsenal makes an incredibly positive impression. Our Data Scientist is fully equipped with the necessary tools and ready for any challenge.
A noteworthy fact is the constant development of architectural solutions dedicated to analytics. Technology industry leaders are constantly trying to systematically overcome all the limitations of the classic formula of a data warehouse (such as support for unstructured data). Databricks with its “Data Lakehouse”[16] concept is a good example. The idea of Data Lake, known for years, introduced the possibility of storing raw data in various formats, but it did not address all the needs of Data Scientists. Data Lakehouse is trying to change this through, inter alia, transaction support, data quality control, or broadly understood data governance (e.g. versioning, support for data consistency and isolation). This is further good news for Data Scientists – some new technologies are designed especially for them!
Are we then just in the title Data Science Heaven, where all difficulties are just a memory of the past, and we are left with unrestrained analytical activity? After all: no. AI / ML projects are characterized by a prominent level of complexity and specific difficulties that do not only result from the selection of tools and technologies (we will deal with this in the next articles in the series). However, tremendous progress in breaking down new barriers is visible to the naked eye. The ML as a service concept just works, and many challenges can be overcome by working with carefully selected partners – such as Elitmind. As a result, Data Science capabilities are available more than ever. So, we can say with a high degree of certainty that even if we are not yet in Data Science Heaven, we are already walking up the stairway leading there.