Elitmind Data Lakehouse – a solution more agile than ordinary data warehouses
18 April 2023
Elitmind’s core business is and always was implementing end-to-end data platforms that intend to unlock the potential of data for our customers. It is quite clear nowadays that data-driven decision-making is becoming the competitive advantage in every market sector. It is also clear that technology is rapidly changing every day and due to the advent of the cloud, it is accelerating even more. The same principle applies to data platforms.
Over the years, many different concepts related to systems dedicated to data analysis have appeared on the market. For those interested in the topic, concepts such as data lake, data warehouse, or data mesh are likely familiar. In this article, a concept will be presented that has become extremely popular for organizations that need to address requirements such as Customer 360, Model Factory, rapid or mature Advanced Analytics capabilities, or relatively easy reporting at a big data scale. Of course, I am talking about Lakehouse, a kind of merge between two different areas: a traditional data warehouse and a data lake from the world of big data processing.
Before we proceed to describe the main topic, let’s say a few words about data warehouses themselves. This approach is not new and dates back to the 1980s. Due to the high level of query complexity and poor performance, the vast amounts of data at that time made it impossible to directly select data for analytical purposes from operational databases. As a result, specialized databases were established to store pre-aggregated and processed data that is optimized for analytical requirements. At that time, technologies such as MPP (Massive Parallel Processing) appeared, which engaged clusters to process data portions in parallel, resulting in much more efficient methods of data analysis. These types of technologies are still used on the market and play a crucial role in modern data projects. An example of this is the Dedicated SQL Pool available in the Azure Synapse Analytics ecosystem. What was and still is relevant from the organizations’ point of view is the approach used during the implementation of this type of solution. Data warehouses ensured an only source of truth, meaning that all data required for analysis is derived from a unified source, ensuring consistency and accuracy in results when the same calculations are performed.
Data is generated from a variety of sources on a large scale today. This includes structured data from relational databases, semi-structured data from website activities, and unstructured data such as images and videos. Traditional databases with parallel or serial processing excel at handling structured data, but they struggle with large volumes of data, and they are not well-suited for handling unstructured forms. This is where big data tools come into play. They can handle large data sets, but they are not optimized for advanced analytics such as machine learning and AI. Therefore, organizations often use specialized tools for advanced analytics, although these tools can connect to traditional databases as a source, it is not an ideal environment for them.
Despite numerous problems, data warehouses have many advantages, such as:
- Recognized technology,
- SQL language, which is used to query structures.
- Transactions and atomicity,
- Data can be updated and deleted,
- Data is clean and organized,
- Data is shared in a standard way that is understandable for all the users,
- Other mechanisms, such as Change Data Capture and Temporal Tables
Due to all these features, many organizations base their analytics on the data warehouse.
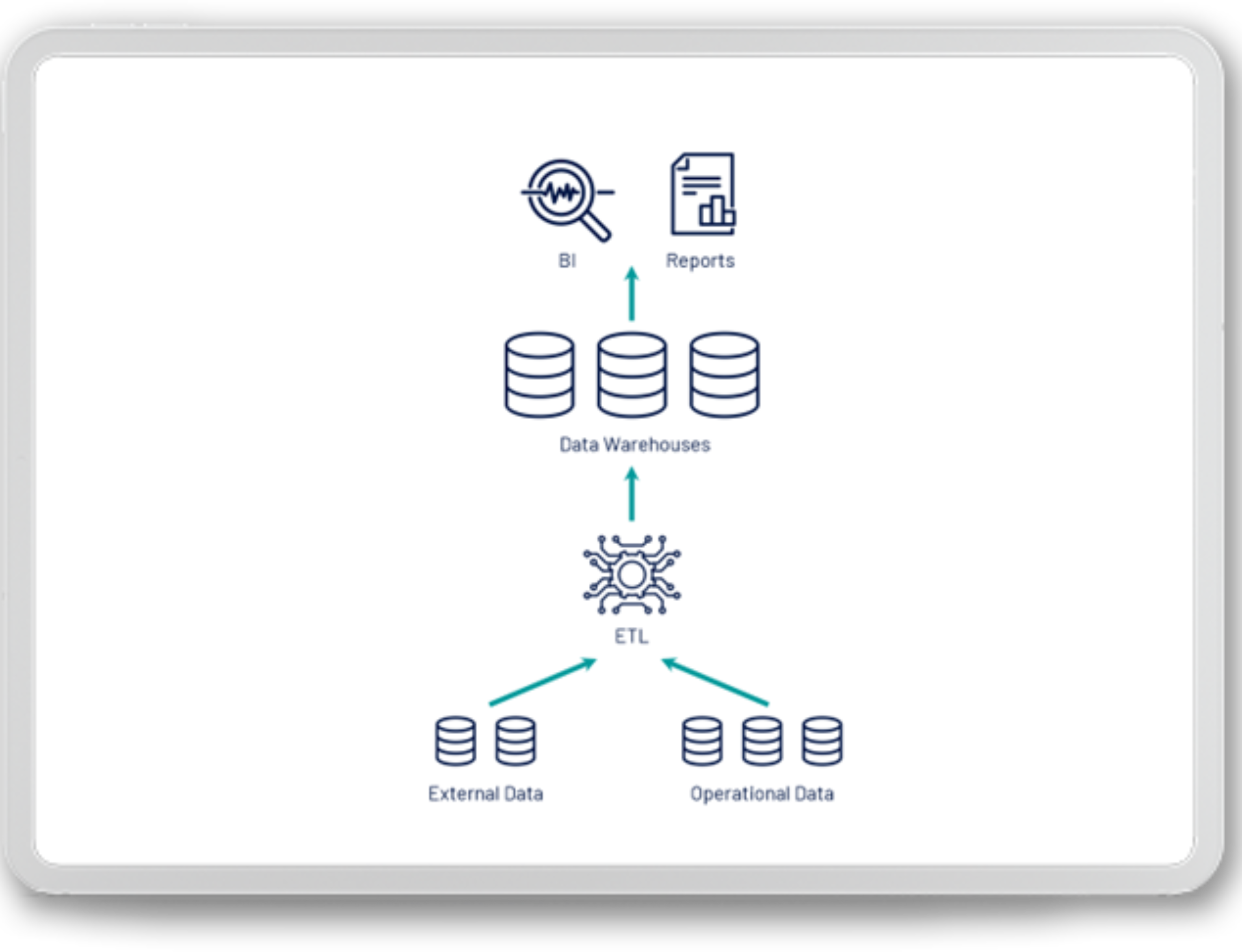
The above image shows a typical high-level data warehouse architecture. Data from various structured sources are regularly downloaded in ETL processes and, after appropriate adaptation, placed in a relational database, which is a data warehouse. It is worth mentioning that the data warehouse itself consists of many layers. On the first layer, we usually have raw data collected from sources. With each subsequent layer, it is transformed into the structure of dimension and fact tables, which facilitate the analysis of this data. The last stage of this type of approach is usually reports or business intelligence tools such as Power BI, which in addition to the visualization layer, also adds a layer of the so-called analytical model where data is stored in a tabular form adapted to the needs of extremely fast data polling. As for the data warehouse itself, several standards and models related to the approach to its construction have also been created. It is extremely important to realize that this standard, despite many years, is still popular and is being implemented or developed all over the world.
For example, a data warehouse can be used primarily in reporting scenarios such as:
- Operational reporting,
- Financial and personnel reports
- Profit and loss statement,
- Inventory levels,
- Analyze what-if scenarios,
- Profiling.
In terms of tools, modern data warehouses have some support for non-tabular data, but this support is limited and should be used as an additional, not a key functionality. For example, the SQL Server database supports storing data in XML, JSON, or even allows storing all kinds of binary objects or long text strings, but it is not the best tool for their processing.
On the other hand, in recent years, a slightly different approach has emerged as a response to the growing needs related to data processing. Organizations have realized that proper data analysis not only gives a competitive advantage but also allows them to keep up with the competition. For this reason, data warehouses began to be insufficient, and there were ideas for data processing, not just from transactional systems and on a slightly much different scale.
Data Lake, as it is the topic here, is an approach derived from big data solutions, which allows for storing huge volumes of data on scalable disks. In this case, when we talk about volume, we’re discussing the lower limit, i.e., “From what size can we talk about big data?” rather than values related to the upper limit. In addition to scalability, an important aspect of the data lake is the fact that we can store data in any form. These can be both extracted relational data and extracted from API interfaces in the form of XML or JSON files, tabular data in the form of PARQUET, CSV files, or even Excel files, as well as video or graphic data. The data lake itself, through full freedom in storage, allows for dumping of any data for analytical purposes without the requirement of having a specific data structure.
A key difference between a data lake and a traditional warehouse is that in a data lake, the format of the data is considered when reading it (schema-on-read), whereas, in a warehouse, the data must conform to a pre-defined schema at the time of loading (schema-on-write). In a data lake, the first layer typically stores raw data in its original format without modification. Only in later stages are algorithms applied to process the data effectively. In warehouses, the data had to be typed from the very beginning and the schema had to be established at the time of loading.
The main advantages of the data lake are:
- Scalability,
- Support for both structured and unstructured data,
- Support for almost any data format,
- The amount of data
- A comfortable working environment for both data engineers and data scientists because of the extensive toolbox customized for both professions.
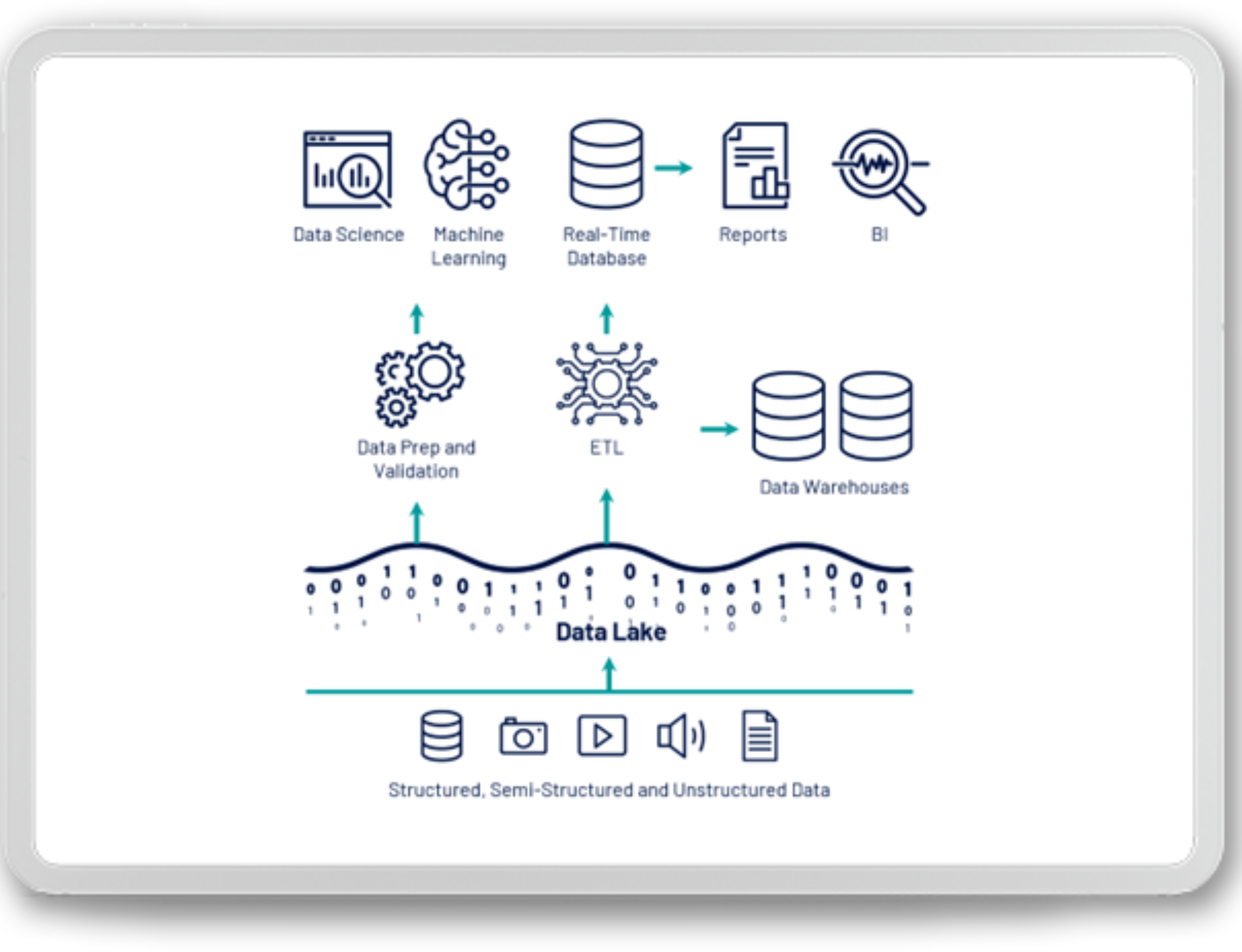
In the picture above, you can see high-level architecture related to the Data Lake. Therefore, we have data from various sources, which then serve other processes within the organization, including the sources of the previously described data warehouse or the use of machine learning or data science algorithms.
Examples of data lake applications in practice are collected for analytical purposes, e.g .:
- materialized stream data from IoT devices, for example
- images captured by city surveillance cameras or security cameras,
- documents and images for pattern recognition or OCR algorithms
- tabular data, which is too large to be analyzed in a traditional data warehouse or relational database.
Of course, there are many more applications, and the above are only examples.
It is worth mentioning that none of the approaches described here is strictly tied to a specific technology, but rather a specific way of organizing and storing data with the scope of operations that should be performed on such data.
As can be seen, both data warehouses and data lakes have unique features that make them suitable for specific applications. With this in mind, over the last few years, an innovative approach has emerged that combines both, called Lakehouse. The concept itself is simply a combination of the words “lake” and “warehouse,” which is logical as it combines the best features of both concepts. The idea is that there will be a standard that guarantees the ability to process all types of data on a large scale, as with the data lake, while also incorporating features typical of a data warehouse, such as easy updating of data, transnationality, and the ability to enforce certain types of data.
The aspect that cannot be ignored is the support for the SQL language, which is also a basic tool in the hands of all kinds of analysts and engineers working with data.
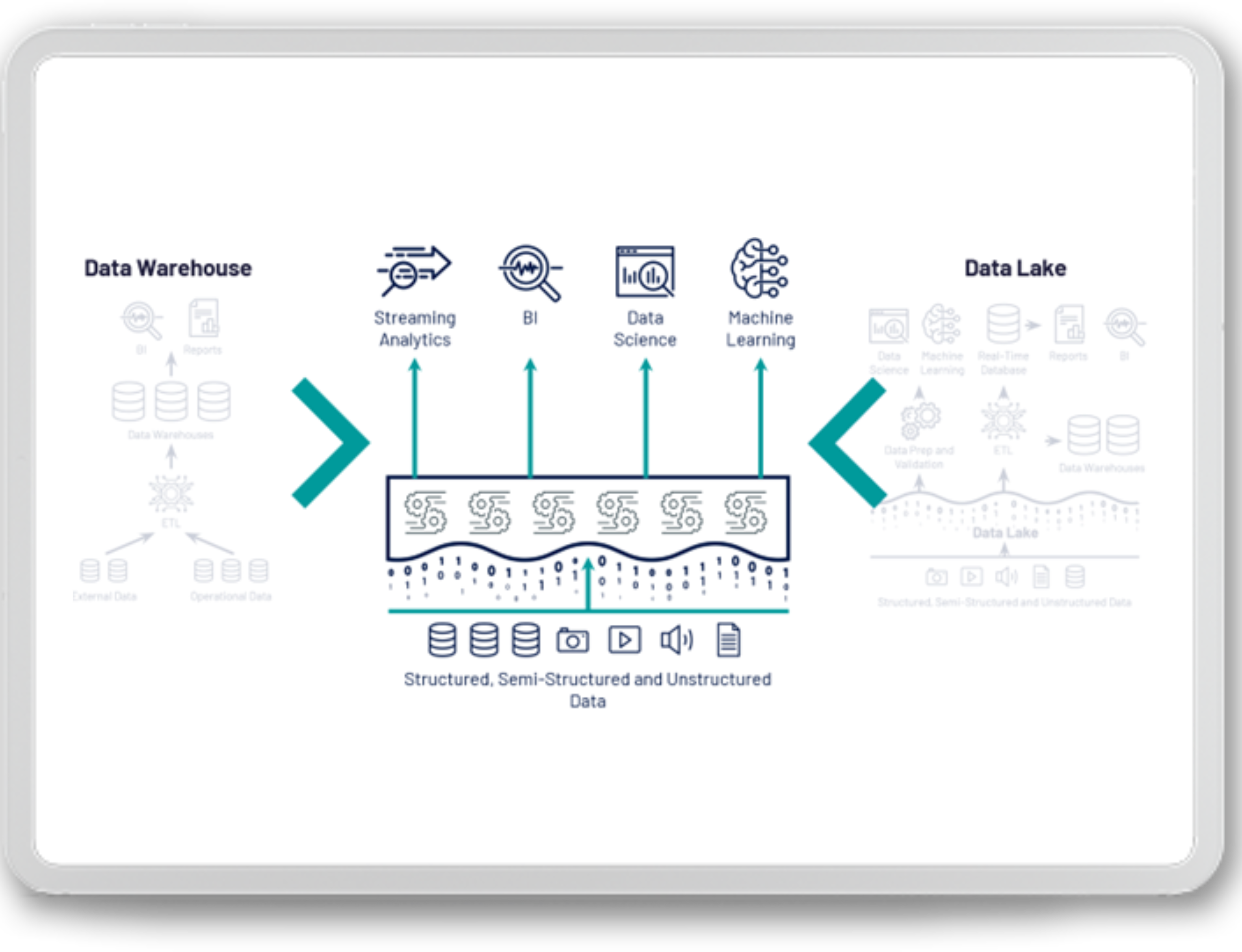
Theoretically, looking at the picture above, we can say that Lakehouse is the next step in evolution and should replace traditional approaches over time. I will try to answer this and a few other questions later in the article.
The first question that may arise is whether the lakehouse itself is a recognized approach or proposed only by a narrow group of specialists. The answer is clear, and we can see that more and more suppliers are offering solutions based on this approach. As part of its Synapse platform, Microsoft has Synapse SQL Serverless, which allows reading data directly from storage and analyzing it using the TSQL language. This service is constantly evolving, and new functionalities are added. These are not the only implementations of this type of solution under the Microsoft banner, as we also have a Spark instance that is part of Synapse, or even database templates based on the same approach supporting the creation of a so-called data lakehouse. (link: https://techcommunity.microsoft.com/t5/azure-synapse-analytics-blog/database-templates-in-azure-synapse-analytics/ba-p/2929112).
In addition to the unique tools provided natively by Microsoft inside the Azure cloud, we also have the Databricks tool, which, based on the Spark engine, allows building solutions based on storage and the delta format, which significantly simplifies certain operations. This format is open-ended, and therefore tools such as the Serverless mentioned earlier, allow it to be read. It is also available in some form in the standard Spark engine. The delta format facilitates many processes such as keeping files the right size, organizing data inside files, and easy loading of new data, including the MERGE operation, which allows for dynamic updating, inserting, or deleting data depending on specific conditions. It’s worth noting that Databricks implements some of the functionalities related to this format only in-house, however, the version available to everyone has all the most important and key aspects.
The key to the effectiveness of any solution based on the Lakehouse concept is appropriate planning of data distribution. Currently, a standard when it comes to the layered approach to the subject is the medallion architecture, an example of which can be seen in the graphic below:
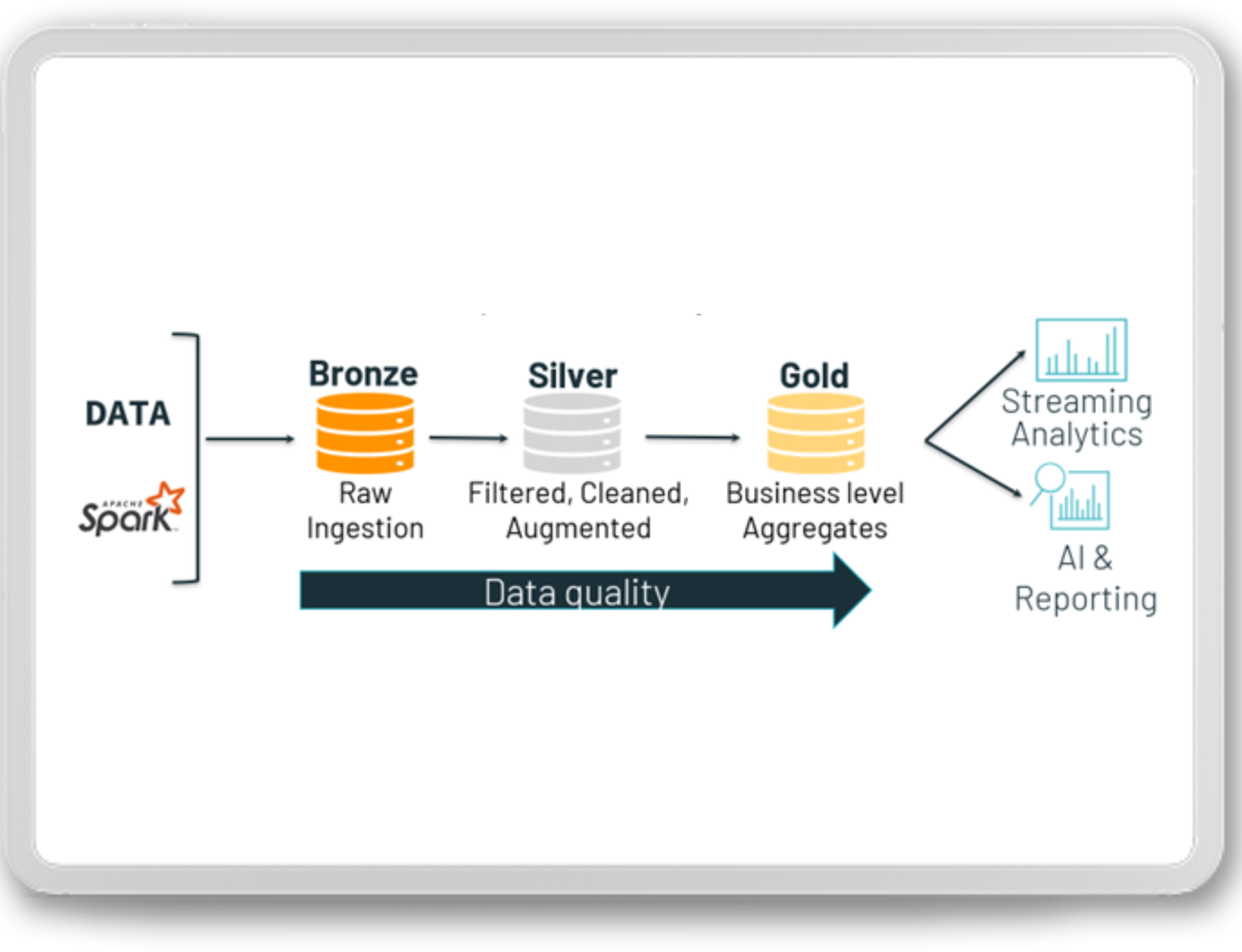
Thus, we have three logical layers (sub-layers can be physically implemented depending on the needs). The brown layer is responsible for storing raw data that has been extracted from the source systems in its native form. It is here that we will find data in various formats, for example, data from REST interfaces take the form of XML or JSON files, tabular data is in the form of PARQUET, ORC, or even CSV, streaming data is JSON or AVRO, and there may also be files like Excel, JPG, TXT, or others related to the information contained inside. The brown layer stores data in the “as is” form from the source system, wrapped with additional metadata, such as the date of extraction, the source system, or information about the content of a specific file. When it comes to organizing your data files into a folder hierarchy, many different approaches are closely related to your specific scenario. Poor data organization can lead to the creation of not only difficult-to-use but also performance-detrimental applications.
An example data lake structure can look like that:
- Layer name
- System name
- Extraction Year
- Extraction Month
- Extraction Date
- File
- File2
- …
- FileN
- Extraction Date
- Extraction Month
- Extraction Year
- System name
This type of approach allows you to easily access specific files and it is possible to perform collective queries where, for example, all files that appeared in a specific month are retrieved. This type of standardization is extremely transparent and favors the efficient design of the data feed processes. Then there is the silver layer, which stores pre-cleaned and filtered data. Only data of analytical or reporting importance is selected here. While the brown layer serves as a landing zone and serves only a technical extraction process, the silver layer can be used for analytical purposes. This is where the delta format usually appears, making reloading data easier. The last layer is gold, which is the counterpart of a data mart. This is where the data is modeled, aggregated, or filtered to meet specific business requirements. Reporting tools or machine learning algorithms connect directly to the gold layer. At this point, the delta format is especially important due to not only its ability to load data but also the built-in mechanisms related to data maintenance and organizing them for reading.
As can be seen, this type of architecture is clear and simple. In practice, of course, there are many combinations of the above approaches, but the idea remains the same in principle. From a technical point of view, the question may arise about how Lakehouse and Databricks fit into the ecosystem of cloud providers. Integration with Microsoft Azure will serve as an example: In Azure, Databricks can be integrated with numerous services such as Azure Data Factory, Azure Data Lake Storage, and Azure Synapse Analytics to build a complete data pipeline. Additionally, Databricks can also be integrated with Azure Active Directory for secure access and Azure Monitor for monitoring and logging. This allows for seamless integration of the Lakehouse approach into the Azure ecosystem, making it easy for organizations to utilize the benefits of both data warehousing and big data processing.

[Source: https://docs.microsoft.com/en-us/azure/architecture/solution-ideas/articles/azure-databricks-modern-analytics-architecture]
The integration of Databricks and Azure allows for seamless integration of Lakehouse components. In the above architecture, batch data is extracted from transactional systems using Azure Data Factory, while streaming data such as logs, and device data is sent to Event Hub and can also be consumed by Databricks. The data storage layer is in Azure Data Lake Storage and can be queried by analytical tools such as Power BI or Azure Machine Learning. It can also act as a source for a traditional data warehouse represented by Azure Synapse Analytics. All of this is embedded in the Azure ecosystem, allowing the use of tools such as Azure Active Directory, Azure DevOps, and Azure Monitor.
By leveraging the deep integration between Azure and Databricks, the Lakehouse approach can be implemented with the use of additional tools and mechanisms, resulting in a comprehensive and integrated system rather than a standalone silo.
In conclusion, it is unlikely that the Lakehouse approach will completely replace data warehouses and data lakes. Instead, it is an extension of the data lake concept, expanding its capabilities and possibilities. While the end of the data warehouse approach has been predicted multiple times, it is still widely used and likely to remain so, but more solutions are moving towards advanced analytics and large-scale data processing, which exceeds the capabilities of traditional data warehouses.