Use All Spark Workers’ CPUs to read from a REST API
2 April 2025
Spark driver and workers:

Recently, we explored how to create our data sources in Spark by using syntax like:
spark.read.format("myrestdatasource")
to read from a REST API.
Now, we’ll examine how to use all worker CPUs to read simultaneously from a REST API.
Key idea
Spark will read in parallel if we define multiple InputPartition objects in DataSourceReader.partitions(). Each partition will cause a separate task to read(partition), allowing multiple simultaneous requests to the REST API.
In addition to the read method, we need to implement a partitions method in our custom class, for instance:
def partitions(self):
"""
Return a list of InputPartition objects. etc.
"""
# Hard-code a couple partitions for demonstration.
# In production, you'd create them dynamically.
return [
InputPartition({'postIdRange': (1, 20)}),
InputPartition({'postIdRange': (21, 40)}),
]
We return a list of partitions. We can specify parameters for each partition, such as a from/to range or an offset/limit.
We can take it one step further by detecting how many cores we can utilize and then generating the number of partitions to match the number of CPUs. For example, if we know our min and max range, we can calculate the size of each partition based on the total number of available cores:
def partitions(self):
# Suppose the total range we want is 1..100
start_id = int(self.options.get("startId", 1))
end_id = int(self.options.get("endId", 100))
total_records = end_id - start_id + 1
# Use an option 'numPartitions' passed from outside (not from SparkContext)
num_partitions = int(self.options.get("numPartitions", 4))
# Compute the size of each partition
chunk_size = math.ceil(total_records / num_partitions)
partitions = []
current_start = start_id
for i in range(num_partitions):
current_end = min(current_start + chunk_size - 1, end_id)
if current_start <= current_end:
partitions.append(
InputPartition({"postIdRange": (current_start, current_end)})
)
current_start = current_end + 1
if current_start > end_id:
break
return partitions
When we execute the code above, we can observe that multiple processes (or tasks) are triggered to query the REST API in parallel, allowing us to utilize all worker CPUs.
from myrest import MyRest
# Register the custom data source with Spark
spark.dataSource.register(MyRest)
default_parallelism = Spark.sparkContext.defaultParallelism
print(f"Default parallelism: {default_parallelism}")
df = (
spark.read
.format("myrest")
.option("startId", "1")
.option("endId", "100")
.option("numPartitions", str(default_parallelism * 2))
.load()
)
Because we returned multiple InputPartitions, Spark runs numerous tasks in parallel. Each call read() with a different subset, letting us download data concurrently.
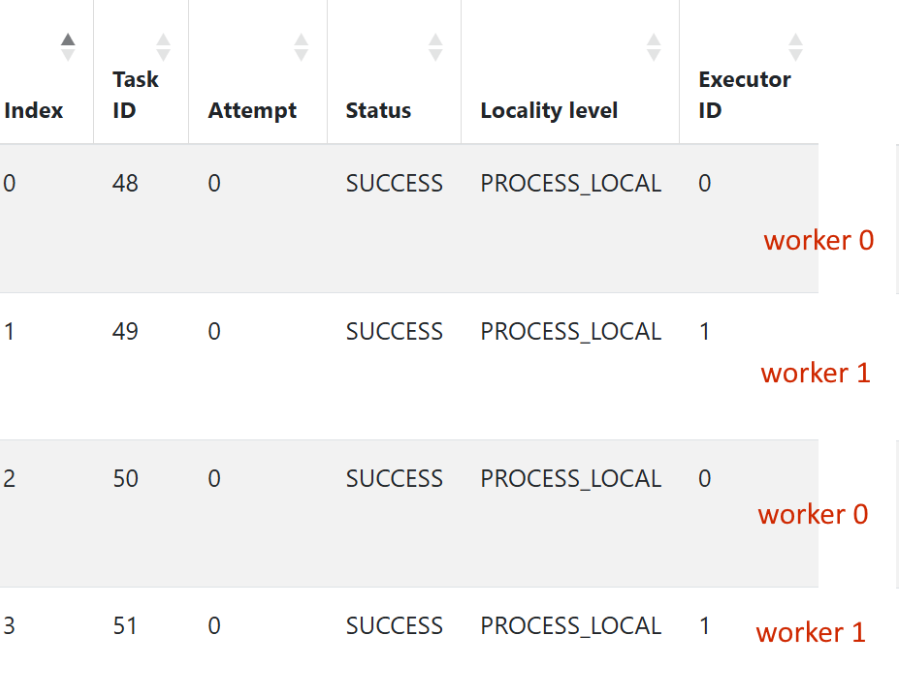
We can see that both workers are downloading data at the same time.
Here is the complete code of our MyRestDataSourceReader class:
import requests
from pyspark.sql.datasource import DataSourceReader, InputPartition
from pyspark.sql.types import StructType
from pyspark import SparkContext
import math
class MyRestDataSourceReader(DataSourceReader):
def __init__(self, schema: StructType, options: dict):
self.schema = schema
self.options = options
def partitions(self):
# Suppose the total range we want is 1..100
start_id = int(self.options.get("startId", 1))
end_id = int(self.options.get("endId", 100))
total_records = end_id - start_id + 1
# Use the Spark default parallelism
sc = SparkContext.getOrCreate()
num_partitions = sc.defaultParallelism
# Compute the size of each partition
chunk_size = math.ceil(total_records / num_partitions)
partitions = []
current_start = start_id
for i in range(num_partitions):
current_end = min(current_start + chunk_size - 1, end_id)
if current_start <= current_end:
partitions.append(InputPartition({
"postIdRange": (current_start, current_end)
}))
current_start = current_end + 1
if current_start > end_id:
break
return partitions
def read(self, partition):
"""
Called on each partition to fetch data from the REST API.
We use the partition's value to filter or pick a subset of data.
"""
# Retrieve partition info
part_value = partition.value # e.g. {'postIdRange': (1, 20)}
(start_id, end_id) = part_value['postIdRange']
url = "https://jsonplaceholder.typicode.com/posts/{id}"
for post_id in range(start_id, end_id + 1):
resp = requests.get(url.format(id=post_id))
resp.raise_for_status()
post = resp.json()
yield (
post.get("userId"),
post.get("id"),
post.get("title"),
post. Get("body")
)
You can download the code which I used in this article from here:
Conclusion
By implementing a custom DataSourceReader with dynamic partitioning, we’ve unlocked the full parallel processing capabilities of our Spark cluster when consuming REST APIs.
This approach significantly reduces data loading times by distributing requests across all available worker CPUs and provides a scalable pattern that automatically adjusts to your cluster’s resources.
As data volumes and API complexity grow, this parallel fetching strategy becomes increasingly valuable for maintaining performance in your Spark-based data pipelines.
Try the implementation in your environment, experiment with partition sizing strategies, and watch your REST API data loading operations reach new efficiency levels.