Custom Spark Data Sources: REST API Made Simple
15 January 2025
Imagine all a data engineer or analyst needs to do to read from a REST API is:

There are no direct request calls or manual JSON parsing – just Spark in the Databricks notebook. That’s the power of a custom Spark Data Source.
In this article, we’ll explore how to build such a connector in Python using Spark’s newer Python Data Source API.
We’ll demonstrate using the JSONPlaceholder public API, which provides fake JSON data.
The big picture
In many organizations, analysts and data scientists often need to grab data from internal or external REST APIs. Typically, they end up writing boilerplate code:
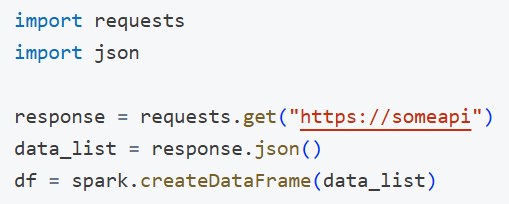
This approach is repeated in multiple notebooks or pipelines- leading to duplication, inconsistency, and maintenance headaches. By creating one custom connector, you:
- Hide the complexity of making HTTP requests.
- Standardize on a single approach for error handling, authentication, etc.
- Let anyone do a simple .format(“myrestdatasource”).option(“endpoint”, “…”).load() to access the data.
We can do this entirely in Python using the new Python Data Source API – already available in Databricks.
Quick Demo: How an analyst would use it
Imagine you’ve created a package named “myrestdatasource” that does all the heavy lifting. Your analysts could then do:

Boom! They get a Spark DataFrame with userId, id, title, and body columns. No more repetitive code – just a consistent DataFrame interface.
Implementation: The core classes
Below is a minimal example of a data source named MyRestDataSource. We’ll use the public JSONPlaceholder API (a fake REST service) for demonstration.
Project structure:

rest_datasource.py:
import libraries
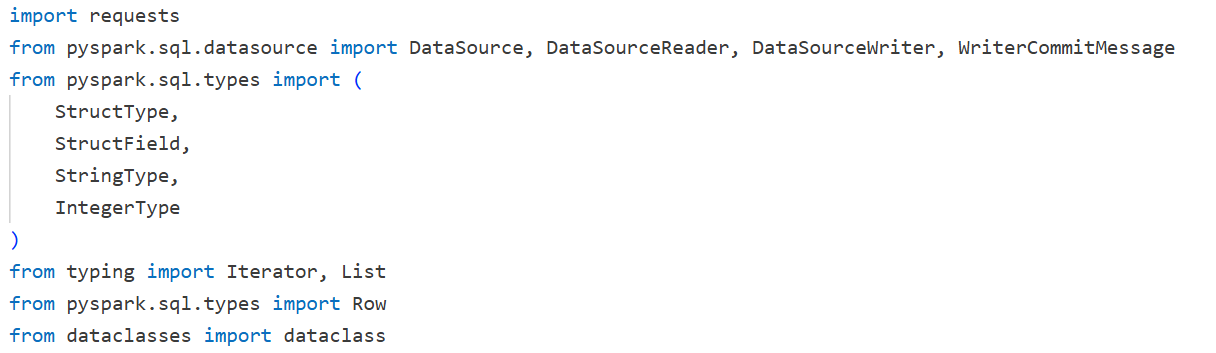
Define a custom DataSource:

Define a DataSourceReader to handle reads:

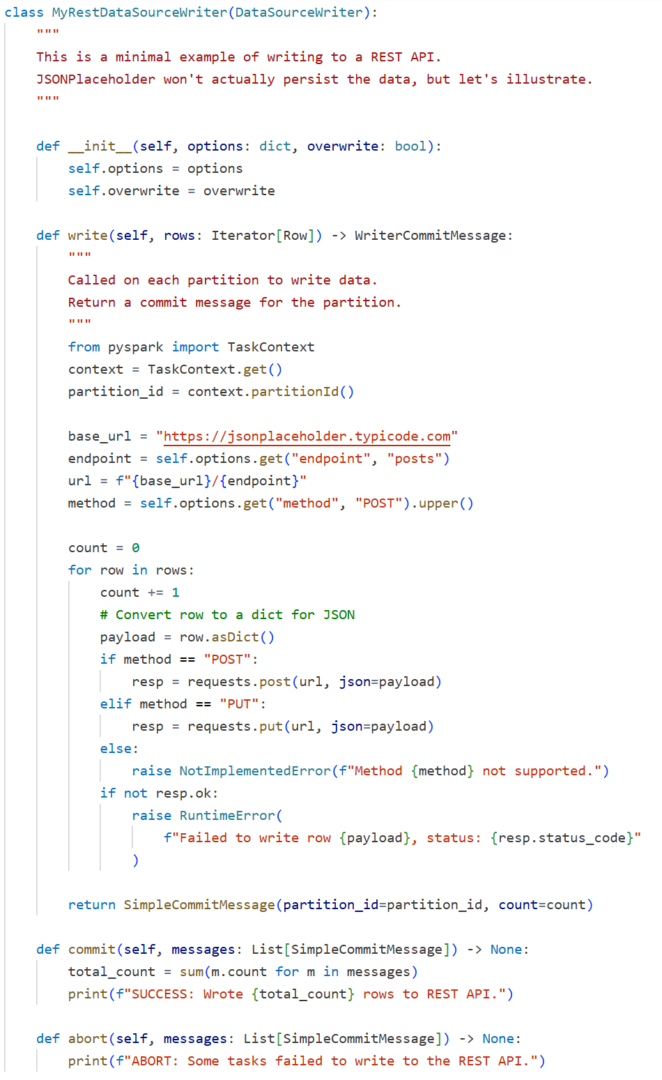
Define a DataSourceWriter to handle writes:
Using in Databricks
To use your data source in a local script or Databricks notebook:

Packaging as a wheel
To share this connector with your team, you can package it as a wheel and upload it to volumes.
Conclusion
By wrapping REST logic into a custom Spark Python Data Source:
- Analysts et a single-line interface to fetch data:

- Engineers standardize how REST calls happen (pagination, error handling, auth tokens) in one place.
- Teams can version and reuse the connector as a wheel in Databricks.
With Spark Python Data Source API, you can create connectors for any REST or proprietary endpoint, unlocking consistent, streamlined data ingestion for your entire organization.
The code used in that article can be downloaded here.
Happy coding, and may your analysts never have to write requests code again!