Exciting New and Hot Features in Microsoft Fabric: A Comprehensive Overview
17 October 2024
If you’re looking to optimize your data management and analytics, you’re in the right place. Microsoft Fabric is constantly evolving, bringing a suite of new features and enhancements to the table. Here’s a deep dive into the latest updates, which are now available or in public preview.
1. General Availability of Copilot for Data Factory
With the general availability of Copilot for Data Factory, creating data integration solutions just got easier. Now, you can leverage natural language to build Dataflow Gen2 solutions, making it simple to articulate your requirements without needing extensive coding knowledge.
Acting as a subject-matter expert, Copilot not only helps you define your needs but also provides clear code explanations, streamlining the entire process. Read more here.
2. Google Cloud Storage and S3 Compatible Shortcuts
Accessing external data has never been easier with the new Google Cloud Storage and S3-compatible shortcuts in Microsoft Fabric. Now generally available, these shortcuts allow you to link directly to your data without the need for pipelines or copying.
This means you can quickly access and analyze your external data within Fabric, saving time and streamlining your workflow. Read more here.
3. Databricks Unity Catalog Integration
With the new Databricks Unity Catalog integration in Microsoft Fabric, seamless cross-system data analysis is now within reach. Thanks to the Mirrored Azure Databricks Catalog feature, you can access Unity Catalog tables directly—no data movement or duplication required.
This integration ensures that your data remains consistent and readily accessible for analysis across different platforms. Read more here.
4. Enhancements to Data Factory Pipelines
Much more efficient and flexible—this best describes the latest updates to Fabric Data Factory pipelines. You can now invoke remote pipelines from Azure Data Factory or Synapse Analytics, expanding your integration capabilities.
Moreover, Spark Notebook environment parameters allow you to reuse existing Spark sessions, cutting down on processing time and streamlining your data operations. Read more here.
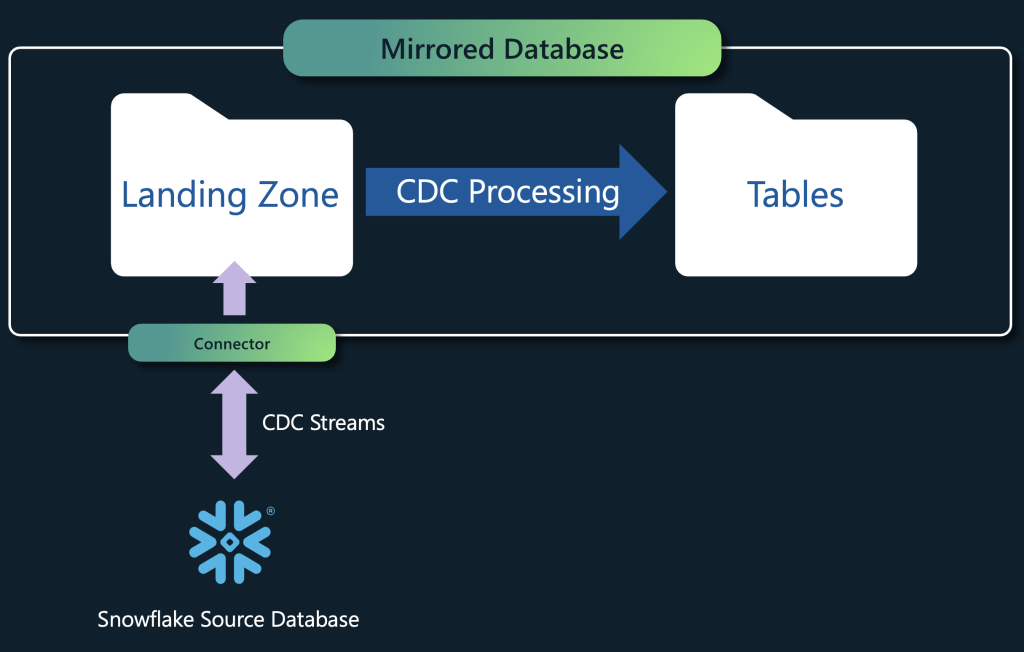
5. Mirroring for Snowflake
Keeping your data up-to-date and accessible just got easier with the general availability of Mirroring for Snowflake.
This feature enables near real-time replication of Snowflake databases into OneLake, ensuring that your data is always current and ready for seamless analysis across all Fabric workloads. Read more here.
6. High Concurrency Mode for Notebooks
Achieve faster startups and save on compute costs with the new high concurrency mode for notebooks. Now available, this feature allows multiple notebooks to share a single Spark session, which enhances overall performance and reduces resource consumption across your pipelines. Read more here.
7. Lakehouse Schemas
Easier data organization is now possible with Lakehouse schemas currently in public preview. By organizing tables into a folder-like structure, this feature streamlines data discovery and keeps your data consistently organized across various engines within Fabric. Read more here.
8. Incremental Refresh in Dataflows Gen2
More good news: you can now keep data processing efficient with the incremental refresh feature in Dataflows Gen2, available in public preview. By updating only the data that has changed since the last refresh, this feature speeds up dataflows and optimizes resource usage. Read more here.
9. New Features for Mirroring Azure SQLDB
Data replication is now more flexible and secure with the latest updates to Mirroring Azure SQLDB. The feature now includes support for schema hierarchy, column mapping, connectivity to SQL databases behind firewalls, and programmatic API management, ensuring enhanced control and security in your data workflows. Read more here.
10. Public Preview of T-SQL Notebook
T-SQL developers can now better manage and document their work with the new T-SQL Notebook, which is available in public preview. This feature supports complex query management and allows for process documentation with Markdown cells, improving collaboration and clarity in project workflows. Read more here.
11. Public Preview of Copy Job
Data movement is simplified with the new Copy Job feature, which is now in public preview. This capability enables efficient copying between various sources and destinations within Fabric, ensuring data consistency and streamlining operations across multiple platforms. Read more here.
12. Tag Your Data
Microsoft Fabric’s new tagging feature significantly enhances data discovery and management. By allowing you to create and apply tags to data items, this feature improves both searchability and organization. With tags, you can categorize data more effectively, making it easier to find relevant content and increasing overall efficiency in data handling. Read more here.
13. General Availability of Fast Copy in Dataflows Gen2
What would you say about efficiently handling large data volumes? That’s now possible with the newly released Fast Copy feature in Dataflows Gen2!
This feature enables rapid ingestion by automatically leveraging a robust backend for large datasets, reducing data processing times and costs. Fast Copy seamlessly adapts to large data sizes with support for various data sources, making it ideal for streamlined data operations. Read more here.
14. Python User Data Functions in Your Data Pipelines:
Want to perform complex data transformations with ease? With Python User Data Functions now available in Microsoft Fabric, you can create custom data processing functions using Python 3.11.
This new feature seamlessly integrates into Fabric’s data pipeline activities, supports various data sources, and gives you the flexibility to handle advanced data validations right within your pipelines. Read more here.
Python illustration generated by Copilot

15. General Availability of Fabric Data Pipeline Support in the On-Premises Data Gateway
Need to bring high-scale data from on-premises sources into Microsoft Fabric? Now you can do it with Fabric Data Pipeline support, which is available in the On-Premises Data Gateway. This feature not only scales up with multi-node cluster support but also offers comprehensive diagnostics logs to simplify troubleshooting. Plus, it provides a unified experience for managing data analytics and integration all in one place. Read more here.
16. Large Data Types in Fabric Warehouse
And the last update comes down to storing more substantial data in your warehouse. With Fabric Warehouse now supporting large data types like VARCHAR(MAX) and VARBINARY(MAX), you can store up to 1MB per cell, far beyond the previous 8KB limit. Plus, performance enhancements ensure you can handle larger textual and binary data with minimal overhead. Read more here.
Final words
And that’s a wrap! These updates reflect Microsoft Fabric’s continued commitment to advancing data management and analytics capabilities. From enhanced integration features to powerful new tools for data handling, Microsoft Fabric empowers users to unlock the full potential of their data.
For further insights, check out our article on Power BI.